Abstract
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space. Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input.
More Demos
AIST++ Dataset
Generated at 128×128, 8fps
Landscape Dataset
Generated at 256×256, 8fps
MoNL & AVDiT
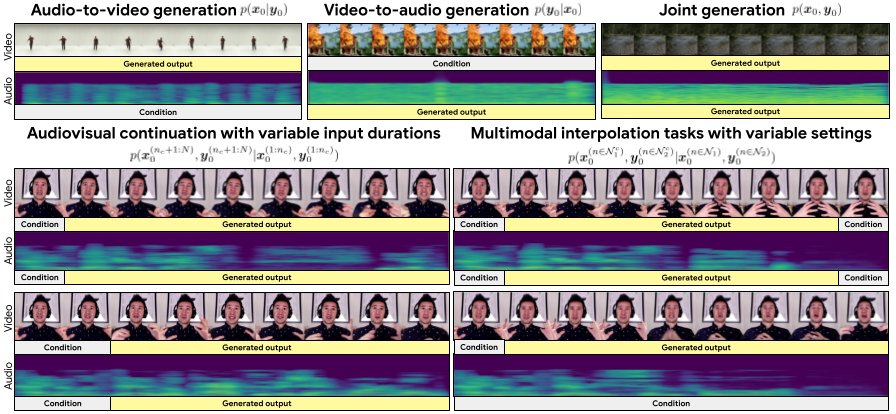
Our Audiovisual Diffusion Transformer (AVDiT) trained with Mixture of Noise Levels (MoNL) tackles diverse AV generation tasks in a single model.
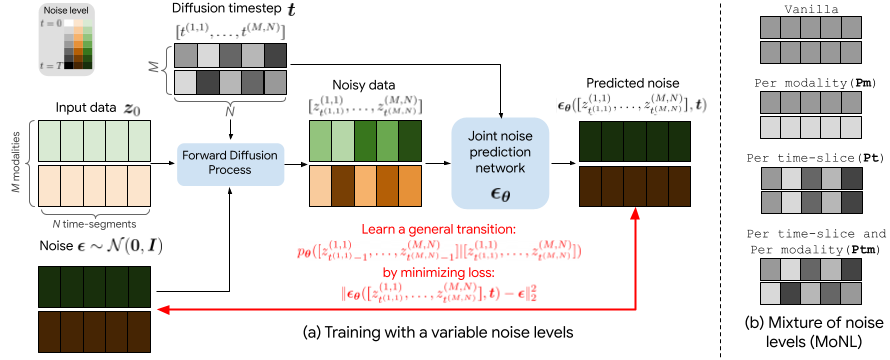
We propose a novel mixture of noise levels (MoNL) to effectively learn arbitrary conditional distributions in the audiovisual space by applying variable noise levels across the temporal dimension and across modalities of the inputs.
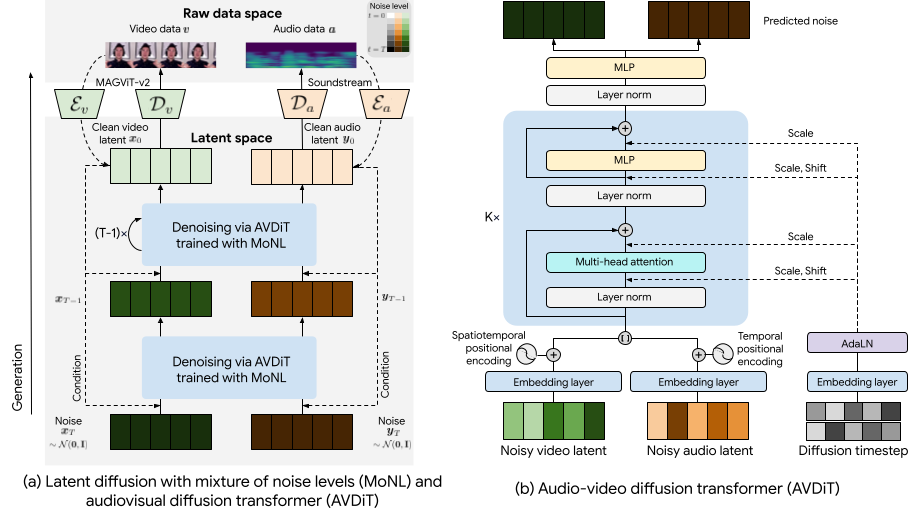
We apply this approach for audiovisual generation by developing a diffusion transformer, (AVDiT).
Comparison with MM-Diffusion
We compare our proposed approach side by side to a few results from the AIST++ dataset for MM-Diffusion (Ruan et. al, CVPR 2023) for various audiovisual generative tasks
Note: We are comparing the generative video results of our model at 128x128 resolution with MM-Diffusion which uses a super-resolution system to get 256x256 videos from videos generated at 64x64 resolution.
Continuation Task
In: First frame of audio and video
Out: Continued audio + video
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion
Ours
MM-Diffusion